

Knochenschall: Das fehlende Glied?
Wer sich auf einer Tonaufnahme sprechen hört erfährt, dass sich die eigene Stimme für andere Menschen anders anhört, als man selbst sie wahrnimmt. Das liegt vor allem daran, dass wir unsere eigene Stimme mit einer Schallkomponente hören, die andere nicht wahrnehmen können: dem Knochenschall.
Die Basics
Knochenschall ist Körperschall – also Schall, der sich in einem Festkörper (Materie im festen Aggregatzustand) ausbreitet. Beim Knochenschall ist dieser Festkörper eben Knochen. Das, was andere Menschen von unserer Stimme wahrnehmen, ist der Luftschall, also Schall, der sich in der Luft – einem Fluid – ausbreitet.
Der Knochenschall ist also der Körperschallanteil unserer Stimme, der von den Stimmlippen ausgehend über unsere Knochenstruktur direkt ans Innenohr wandert und nicht über die Luft, das Außenohr, Trommelfell und Mittelohr in die Hörschnecke gelangt.
Ein grundlegender Unterschied zwischen beiden Schallarten ist, dass sich in einem Fluid wie der Luft nur Longitudinalwellen (eine physikalische Welle, die in Ausbreitungsrichtung schwingt) ausbreiten können, während in einem Festkörper zusätzlich Transversalwellen (physikalische Wellen, bei denen die Schwingung senkrecht zu ihrer Ausbreitungsrichtung erfolgt) ausbreiten können . Wenn es zu sogenannten Kopplungen beider Wellenarten in dünnen Bauteilen wie zum Beispiel Platten oder Balken kommt, können Biegewellen entstehen, bei denen wiederum Biegeverformungen auftreten können. Dank ihrer hohen Schallenergie produzieren die Biegewellen dann wiederum Luftschall – man denke an elektrostatische oder planar-magnetische Lautsprechermembranen, oder aber ganz einfach an eine Glocke (Platte), oder ein Triangel (Balken). Auch Sänger und Chorleiter nutzen die Konchenschallübertragung mit einer Stimmgabel am Oberkieferknochen oder der Schläfe, um die präzise Tonhöhe für den Beginn eines Stücks sicherzustellen – und nur so können sie den leisen Klang der Stimmgabel selbst in lauten Umgebungen klar hören.
Die Schallgeschwindigkeit beim Körperschall ist stark abhängig von den Eigenschaften des Festkörpers. Dazu gehören vor allem die Dichte, die Schallhärte, die Querkontraktionszahl sowie der Elastizitätsmodul (Longitudinalwellen) und der Schubmodul (Transversalwellen).
Ein grundlegender Unterschied zwischen beiden Schallarten ist, dass sich in einem Fluid wie der Luft nur Longitudinalwellen (eine physikalische Welle, die in Ausbreitungsrichtung schwingt) ausbreiten können, während in einem Festkörper zusätzlich Transversalwellen (physikalische Wellen, bei denen die Schwingung senkrecht zu ihrer Ausbreitungsrichtung erfolgt) ausbreiten können. Wenn es zu sogenannten Kopplungen beider Wellenarten in dünnen Bauteilen wie zum Beispiel Platten oder Balken kommt, können Biegewellen entstehen, bei denen wiederum Biegeverformungen auftreten können.
Dank ihrer hohen Schallenergie produzieren die Biegewellen dann wiederum Luftschall – man denke an elektrostatische oder planar-magnetische Lautsprechermembranen, oder aber ganz einfach an eine Glocke (Platte), oder ein Triangel (Balken). Auch Sänger und Chorleiter nutzen die Konchenschallübertragung mit einer Stimmgabel am Oberkieferknochen oder der Schläfe, um die präzise Tonhöhe für den Beginn eines Stücks sicherzustellen – und nur so können sie den leisen Klang der Stimmgabel selbst in lauten Umgebungen klar hören.
Die Schallgeschwindigkeit beim Körperschall ist stark abhängig von den Eigenschaften des Festkörpers. Dazu gehören vor allem die Dichte, die Schallhärte, die Querkontraktionszahl sowie der Elastizitätsmodul (Longitudinalwellen) und der Schubmodul (Transversalwellen).
Nur halb innovativ umgesetzt?
Gewöhnliche Headsets berücksichtigen den Knochenschall nicht und nehmen beim Freisprechen nur den Luftschall des Sprechers oder der Sprecherin via Mikrofon wahr – und leider auch jeden Schall, der um sie herum existiert; Störschall wie Straßenlärm, Wind und Regen, vor allem aber andere Sprecher. Gerade in störschallerfülten Umgebungen bietet die Knochenschallübertragung viel Potenzial, die Qualität des Freisprechens bei In-Ear-Headsets zu verbessern. Hersteller nutzen dieses Potenzial mit speziellen, meist piezoelektrisch arbeitenden Mikrofonen (Knochenschallsensoren) – verspielen jedoch viel davon, weil sie den Knochenschall entweder bisher beim Testen gar nicht berücksichtigen und daher ihre Produkte nicht dementsprechend optimieren oder weil sie nicht standardisierte Tests mit unter Umständen wenig belastbaren Ergebnissen durchführen.
Ganzheitlich testen
Hier setzt HEAD acoustics an: Wir ermöglichen vollumfängliche Tests von Headsets mit Knochensachallsensoren. Dazu nutzen wir unseren Kunstkopf HMS II.3 LN HEC in der ViBRIDGE-Version und regen die Teile unserer Künstlichen Ohren HEL/HER 4.4, die den Knochen des menschlichen Kopfes entsprechen, mit einem Vibrationserzeuger (Aktuator) an, wie die Stimme eines Menschen es auch tun würde. Das hört sich wahrscheinlich erst mal nicht übermäßig kompliziert an. Doch wenn man es wirklich richtig machen will – und das ist immer unser Anspruch – ist es eine beachtliche Herausforderung, ein solch realistisches Knochenschallsignal zu generieren und über geeignete Bauteile des Künstlichen Ohrs an die Knochenschallsensoren von In-Ear-Headsets zu übertragen.
Wie viel Knochenschall darf’s denn sein?
Das Problem war vor allem, dass bis vor kurzem niemand wirklich wusste, welche Frequenzanteile der Stimme am Innenohr – dort wo sich die Körperschallaufnehmer befinden – in welcher Lautstärke ankommen. Um dieser Frage auf den Grund zu gehen, haben wir eine ganze Reihe von Messungen mit menschlichen Sprecher:innen durchgeführt und mit Hilfe von In-Ear-Headset-Nachbildungen mit Knochenschallsensoren gemessen, wie sich der Knochenschall eben „anhört“. Aus den Ergebnissen dieser umfangreichen Tests konnten wir ableiten, dass sich die Körperschallübertragung zwischen Frauen und Männern nicht signifikant unterscheidet, dass sich aber männliche Stimmen besser für unsere Zwecke eignen, da Frauen eine höhere Stimmgrundfrequenz haben und somit die Übertragung des Körperschalls im tieffrequenten Übertragungsbereich dort nicht messbar ist.
Die Messungen ermöglichten es uns, einen guten Überblick darüber zu erhalten, wie die individuellen Unterschiede bei den einzelnen Sprechern aussehen. Aus den Ergebnissen dieser Streuungsanalyse leiteten wir mittlere Übertragungsfunktionen ab, die uns als Grundlage für eine wirklich realistische Körperschallsimulation in maßgeschneiderten Tests im Labor dienen. Anders gesagt: Wir bilden ein Körperschallsignal nach, das erstmals den Ergebnissen der Messungen aus unseren Tests entspricht. Das erzeugen wir mit Hilfe des erwähnten Aktuators im künstlichen Ohr des Kunstkopfes HMS II.3 LN-HEC parallel zu dem durch die Luft übertragenen Stimmsignalanteil, den unser Fullband-fähiger künstlicher Mund mit einem Zwei-Wege-Lautsprecher generiert.
Selbstverständlich stellen wir sicher, dass die von uns generierten Signale im Bereich der beim Menschen stattfindenden Körperschallübertragung liegen: Ein Vergleich der Messergebnisse aus den Tests mit menschlichen Sprechern und den Simulationen mit ViBRIDGE zeigt eine klare Korrelation: Unsere Simulationsergebnisse stimmt mit den echten menschlichen Ergebnissen überein. Das bedeutet: Mit HEAD acoustics ViBRIDGE können Headset-Hersteller ihre Headsets mit Körperschallsensoren durch die Simulation des Knochensachalls im Labor ganzheitlich, korrekt und zuverlässig testen.
Warum Headset-Hersteller die Knochenschallübertragung berücksichtigen müssen
Eine bessere Trennung der Stimme von Lärm oder konkurrierenden Sprecher:innen liefert die perfekte Grundlage für eine optimale Geräuschunterdrückung und verbessert ganz grundsätzlich die Sprachqualität in lauten Umgebungen. Doch das ist nicht alles: Aufwändige Technologien wie die Echounterdrückung und anderer Signalverarbeitungen in Headsets profitieren ebenfalls von einer perfekten Stimmerkennung – die Übertragung des Knochenschallanteils der Stimme führt zu einem vorab bereits perfekt entstörten Sprachsignal.
Hier zeigen wir ein Beispiel für die Möglichkeit, Störschall mit Hilfe von Körperschallsignalen besser zu unterdrücken. Stellen Sie sich vor, Sie bewegen sich während eines Telefonats aus einem ruhigen Raum in eine Kantine. Die Hintergrundgeräuschsituation ändert sich dabei abrupt. Diese Änderung können wir einfach im Labor simulieren, indem wir nach Beginn der Sprachwiedergabe über den Mund des Kunstkopfs das entsprechende Hintergrundgeräusch über ein Hintergrundgeräuschsimulationssystem wie 3PASS lab oder 3PASS flex einspielen (Abb. 1).
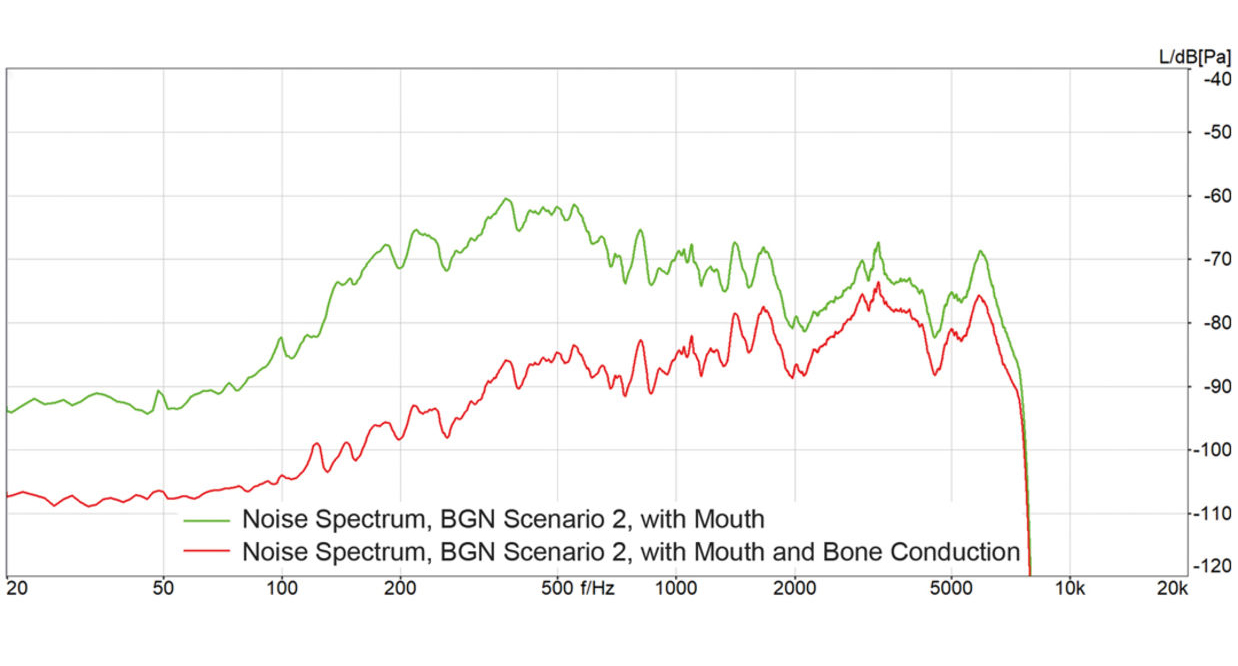
Der Noise Canceller des Headset-Mikrofons muss plötzlich mit einer völlig veränderten Hintergrundgeräuschsituation zurechtkommen und soll dennoch das Hintergrundgeräusch möglichst effektiv unterdrücken und gleichzeitig die Qualität des Sprachsignals möglichst gut erhalten. Genau dabei hilft der Knochenschallsensor enorm: Der Abgleich des Knochenschallsignals mit dem per Mikrofon eingefangenen Luftschall trennt die Sprache der Nutzer:innen eindeutig vom Hintergrundgeräusch und verbessert so die Adaption der Geräuschunterdrückung. In jeder kleinen Sprachpause kann der der Noise Canceller das Hintergrundgeräusch „schätzen“ und den „Antischall“ (eine zum Geräusch gegenphasige Schallanregung) präziser generieren. Im Resultat zeigt sich dann eine messbar schnellere und verbesserte Adaption an das Störgeräusch: Abbildung 2 zeigt das gemessene Leistungsdichtespektrum des Hintergrundgeräuschs für ein Headset mit und ohne Körperschallsimulation durch den Kunstkopf. Man sieht deutlich, dass bei Simulation der Körperschallanregung über den gesamten Frequenzbereich eine Reduktion des Störgeräuschs um zwischen 8 und 28 dB möglich ist. Diese erhebliche Verbesserung ist nur durch die Verwendung des Körperschallsignals möglich .
Was braucht man?
Wie Sie sehen, ist die Körperschallsimulation beim Testen entsprechender Headsets von entscheidender Bedeutung. Nur mit einer standardisierten, sich ergänzenden Simulation von Luft- und Körperschallanteilen, die durch die menschliche Stimme erzeugt werden, ist es möglich, Headsets in verschiedenen Gesprächssituationen objektiv reproduzierbar und ganzheitlich zu bewerten und zu optimieren. HEAD acoustics bietet eine komplette All-in-One-Lösung zum Testen, Optimieren und Validieren entsprechender Headsets.
Für die Simulationen nutzen wir neben dem Kunstkopf HMS II.3 ViBRIDGE und den Künstlichen Ohren HEL/HER 4.4 ViBRIDGE unsere Software für automatisierte Hintergrundgeräuschsimulation, 3PASS lab, im Zusammenspiel mit labCORE, der modularen Hardware-Plattform für Tests der Sprach- und Audioqualität, und der Mess- und Analysesoftware ACQUA zur Steuerung des gesamten Testablaufs.

Bessere Spracherkennung
Perspektivisch lässt sich auch über eine Verbesserung der Spracherkennung durch Knochenschallsimulation im Zusammenspiel mit der Spracherkennungs-Testsoftware VoCAS nachdenken. Dazu müssen jedoch systematische Untersuchungen stattfinden, um die Strategien zur Geräuschreduktion bei Spracherkennung zu definieren.